


When applied to physics-based motion imitation, ADD achieves comparable performance to the SOTA motion tracking method, DeepMimic, without the reliance on manual reward engineering.
Tired of designing and tuning reward functions? ADD can help! ADD is an adversarial Multi-Objective Optimization (MOO) solution that is broadly applicable to a range of problems, including motion tracking. It automatically balances the various objectives, reducing the burden of manual reward engineering and weight tuning. With ADD, designing reward functions can be as simple as calculating the raw errors, and let the discriminator do the heavy lifting of turning them into effective training signals for you!
AND it is an adversarial framework trained using only ONE positive sample.
When applied to physics-based motion imitation, ADD achieves comparable performance to the SOTA motion tracking method, DeepMimic, without the reliance on manual reward engineering.
Blue: ADD | Green: Reference Motion
While DeepMimic, relying on a set of hand-tuned weights, fails to reproduce the challenging parkour motions (e.g., Climb and Double Kong), ADD is able to successfully imitate these motions and the intricate contacts with the objects without any manual tuning.
With the automatic balancing of objectives, ADD can easily transfer to characters of different morphologies without the need for significant retuning.
Blue: ADD | Green: Reference Motion
Beside motion imitation, ADD is applicable to a variety of multi-objective problems. An example is training a quadruped robot to walk naturally while following steering commands.
Beside motion imitation, ADD is applicable to a variety of multi-objective problems. An example is training a quadruped robot to walk naturally while following steering commands.
With ADD, switching between tasks involves less manual engineering, as it greatly reduces the need to design task-specific rewards and re-tune hyperparameters from scratch.
This quadruped controller, trained using ADD, demonstrates natural gaits while closely following user-provided steering commands, without the use of reference motions.
A common approach to tackling MOO problems is to aggregate the objectives, li(θ), into a weighted sum. While simple and widely used, it relies on manual weight tuning and can miss nuanced trade-offs.
We propose to construct a non-linear aggregation of the objectives using an Adversarial Differential Discriminator (ADD), which enables our method to automatically learn more flexible and dynamic combinations of the objectives.
ADD receives, as negative samples, vectors of losses Δt, representing the difference between the policy’s performance and the target. For motion tracking, Δt corresponds directly to the raw, per-frame tracking errors. The only positive sample is the zero vector, which represents the ideal case of zero error for every objective.
To avoid the discriminator from overfitting to always assigning score of 1 to the zero vector and 0 to everything else, we introduce a gradient penalty regularizer. This regularization encourages smooth decision boundaries and provides informative gradients for the policy.
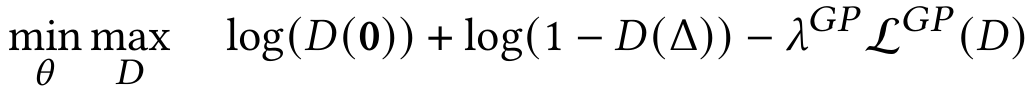
During training, the policy (or model in general) adjusts its parameters 𝜃 to drive Δt closer to zero to fool the discriminator. Meanwhile, the discriminator dynamically attends to different objectives and hones in on the more difficult combinations of objectives to continually challenge the policy.
Because of this adaptive interplay, ADD is able to simplify reward function design. For instance, in motion tracking applications, ADD greatly reduces the number of hyperparameters that need to be carefully tuned.

@inproceedings{
zhang2025ADD,
author={Zhang, Ziyu and Bashkirov, Sergey and Yang, Dun and Shi, Yi and Taylor, Michael and Peng, Xue Bin},
title = {Physics-Based Motion Imitation with Adversarial Differential Discriminators},
year = {2025},
booktitle = {SIGGRAPH Asia 2025 Conference Papers (SIGGRAPH Asia '25 Conference Papers)}
}